Michael Lawrence García

Accelerating computational mechanics with machine learning.
 Unfiltered Taylor-Green Vortex vs. Filtered with Exact SGS Model
Unfiltered Taylor-Green Vortex vs. Filtered with Exact SGS Model
Research
During my undergrad, I conducted research at Cal. State Long Beach, Columbia, and Caltech on various topics and independently secured over $17,000 in grants from NASA and Columbia Engineering in support of my efforts. While the nature of the research I accomplished varied from lab to lab, each carried a fluid mechanics motif. The following has been adapted from my NSF Graduate Research Fellowship Program application.
CSU Long Beach
My freshman summer was spent working for the Solid Rocket and Combustion Laboratory (SPACL) at California State University, Long Beach (CSULB) under Prof. Joseph Kalman. There I analyzed synchrotron data from the combustion of a HTPB solid rocket motor with aluminum additives. The project mostly consisted of using MATLAB’s image processing libraries to detect and track molten aluminum particles as they left the fuel grain during combustion. While it was satisfying work, my biggest takeaway from the research I did at CSULB was that I enjoyed simulation and computation far more than I expected. I thoroughly enjoyed sifting through code that I had written and feeling the ultimate sense of satisfaction from fixing a bug that had plagued me for some time.
This was also the first introduction I had to scientific programming, which is a completely different way of thinking from the traditional programming paradigm. Every hour coding was doubled or tripled in verification. I struggled at first, but soon came to appreciate the increased rigor. Before I started my foray into research, I professionally and academically vacillated between high performance computing and intelligent systems to the far off world of propulsion engineering. My research at SPACL showed me that computational engineering had a host of highly relevant applications in aerospace. In this way, I realized my passions were not mutually exclusive. More importantly, the experience gave me a taste for how intellectually rewarding the life of an academic could be.

Columbia
I took the lessons I learned at CSULB and brought them to a lab at Columbia performing large eddy simulation (LES) research during my sophomore year. I worked at the Environmental Flow Physics Laboratory (EFPL) developing particle transport simulations. There I was introduced to the even more obfuscated programming language of Fortran, the long-time gold standard for high performance computing. Here I struggled more than I did at CSULB. All the relevant papers virtually piled high in citation management software. For months, I did nothing but test Fortran code and read the relevant literature on Lagrangian particle transport solvers. The end goal was to test this code on Covid particle droplets, but the light at the end of the tunnel was dim. Nevertheless, I persisted on. I excitedly welcomed the challenge and by the end of my Sophomore year was very comfortable with running LES simulations with the code I made on Columbia’s high performance computing clusters. I was then awarded a $5,000 Bonomi scholarship by Columbia’s Civil Engineering and Engineering Mechanics Department to continue the particle dispersion research over the summer.
Caltech
In the summer after my sophomore year, I continued refining the code I helped write and ran simulations using it. As I moved further along in the project, I became increasingly fascinated with the idea of applying an artificial neural network (ANN) to this problem. While I had yet to be exposed to intelligent systems, I had a marginal suspicion that they could do a better job of accurately dispersing particles in a flow field than the colossal, stochastic code I wrote ever could. My knowledge of the underlying mathematical formulations behind LES were still infantile, yet I wanted to learn more. The particle transport solver finally coded but my search for knowledge still unsatisfied, I ventured across the country to the Bae Research Group at Caltech.
Caltech gave me a place to thrive and truly grow as a researcher. Now, I had experience with LES and the numerical methods of CFD to a level where I could valuably apply myself to turbulence research at a high level. I sought out and acquired funding from Columbia to work with Prof. Jane Bae on using ANNs in LES in a way which was more physical than previous research. I applied for and accepted an offer to join Caltech’s Visiting Undergraduate Research Program (VURP) with the money I received from Columbia’s Engineering Internship Fund and the support of two faculty. As part of the program, I had to write three mid-project and one final reports and make and give a presentation about the work I conducted over the summer. My research began by first reviewing everything I knew about LES and using it to develop my own codebase.
To ensure I truly understood LES at a level which I found satisfactory, I rewrote a MATLAB direct numerical simulation (DNS) codebase from scratch in Python for use in a data-driven turbulence model. This was an extremely difficult task which, like my other research efforts, I accepted happily. Many hours of writing, rewriting, verification, and re-verification were spent on this codebase. In a week I had completed a preliminary DNS code for solving the Navier-Stokes equations. Then I implemented LES onto this program. In doing so I became highly confident with my ability to use, create, and understand the numerical method underpinnings behind LES to a level which I need for a graduate program. I was very happy to see the culmination of my previous work and my newfound sense of my perspective on CFD. After this initial code was verified against an existing LES solver, I moved on to implementing a machine learning (ML) model for turbulence into the code.
While I had been exposed to ML models before, I had never worked to develop an ANN on my own. However, my passion and interest for high performance computing and aerospace outweighed my trepidation. I dived into ML by constructing a larger model from small building blocks of code, much like how other methods of programming for scientific computing are conducted. With the years of experience I had in scientific computing and my club work building robots and rockets, I was able to break down a problem I had no knowledge of or expertise in into actionable tasks. By the end of the summer, I was fluent with both LES and the principles of ML. I had created a preliminary data-driven turbulence model which I am refining in my last year of undergraduate college in advance of a publication.
My most recent strides into aerospace research primarily dealt with presenting research to professionals and my peers. I presented to the Bae Research Group about the nature of my summer research before giving a talk at one of Caltech’s annual summer research symposiums.These Caltech events made me well prepared to give a presentation on my research at places where I can convey the work I did to industry and academic professionals. To this end, I gave a talk at the American Physical Society’s Division of Fluid Dynamics in Washington, D.C. last November. In preparing for these presentations, I have felt myself become more confident with my own understanding of the material in real time. Through my search for funding for my continuing research and travel costs, I won a competitive Minorities in STEM Fellowship from the New York Space Grant. In total, I independently procured over $11,000 of funding for this project.
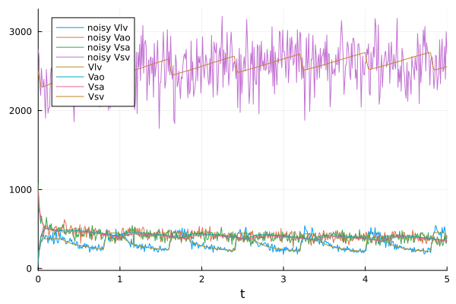
Current Work
My current work involves parameter estimation for coupled systems of ordinary differential equations using Bayesian Neural Networks (BNNs). In particular, I am training a model to rapidly estimate the parameters of a heart model for pediatric borderline left ventricle. This is done in the hope of informing surgery decisions. Previous work used feed-forward ANNs which could not perform uncertainty quantification (UQ) on their estimates. UQ was typically generated via Markov-Chain Monte-Carlo (MCMC) techniques which are computationally intensive compared to BNNs. GPU acceleration is paramount in these efforts as BNNs benefit massively from parallelized computing.